I'm going to illustrate how I interpret my Oracle results, because I still see a lot of people asking "what do my Oracle results mean?" If you haven't already, you may want to read
my intro guide to Gedmatch's Admixture and Oracle, but I'd like to elaborate on that a little bit.
Firstly, it's important to remember that the results can be very speculative and it's best not to take them very literally. People in neighboring regions simply share too much DNA to always be able to tell them apart with accuracy. That means the more narrowed down the areas are in the result, the more speculative it is. You could be German, for example, and get French results because they are neighboring countries who share a lot of DNA. It doesn't mean you're French, it just means this particular calculator put that French/German shared DNA into French instead of German.
 |
| Eurogenes K13 Oracle 4, using 4 populations approximation |
Secondly, your results are going to be different for each calculator you use so don't just stick to one, explore all those which apply to your background (ie, don't go using Ethiohelix when you're 100% European). Certain calculators may give you more or less accuracy than others. In my personal experience, Eurogenes K13 Oracle 4 (right) isn't very accurate. It really wants me to be Jewish and I'm really not - I have no known Jewish ancestry and don't get any Jewish results from any of the big 4 companies, or in any of Gedmatch's Admixtures. It crops up in the odd Oracle result, but none so much as Eurogenes K13 Oracle 4 populations. I personally have found K15 and EUtest Oracle's to be more accurate, and since K15 is a more recent version of EUtest, that's what I'm going to use to demonstrate how to read Oracle results in some more depth than before.
I find the best thing to do is rather than look at your Oracle results and try to pick one combination that fits you best, or shows the closest distance, look at the results on the whole. Which populations are you seeing the most? Which ones the least? Although I like to look at 4 populations the most because I am primarily from 4 different regions in Europe, you can also look at the 1, 2, and 3 populations modes.
These are my Eurogenes EUtest V2 K15 Oracle 4 results:
1 Orcadian + South_Italian + West_German + West_German @ 4.425306
2 French + South_Italian + West_German + West_Norwegian @ 4.689746
3 South_Italian + Southwest_English + West_German + West_German @ 4.689806
4 East_Sicilian + Orcadian + West_German + West_German @ 4.747531
5 Italian_Jewish + Orcadian + West_German + West_German @ 4.835878
6 East_Sicilian + Southwest_English + West_German + West_German @ 4.850750
7 Italian_Abruzzo + West_German + West_German + West_German @ 4.853912
8 North_Dutch + South_Italian + West_German + West_German @ 4.863277
9 French + Orcadian + South_Italian + West_German @ 4.911067
10 South_Italian + Southeast_English + West_German + West_German @ 4.914701
11 Tuscan + West_German + West_German + West_German @ 4.922722
12 Central_Greek + Orcadian + West_German + West_German @ 4.922800
13 South_Italian + West_German + West_German + West_Norwegian @ 4.927629
14 Irish + South_Italian + West_German + West_German @ 4.941526
15 South_Italian + West_German + West_German + West_Scottish @ 4.958009
16 East_Sicilian + French + West_German + West_Norwegian @ 4.978409
17 East_Sicilian + French + Orcadian + West_German @ 4.982550
18 South_Italian + West_German + West_German + West_German @ 5.005996
19 South_Italian + Spanish_Galicia + West_Norwegian + West_Norwegian @ 5.010231
20 Central_Greek + Southwest_English + West_German + West_German @ 5.011045
So rather than saying the top results must be the most accurate because it's the closest distance, and determining it to be only somewhat accurate because it did identify my German, Italian, and Scottish ancestry, but not my English or Norwegian, let's look at the entire results as a whole.
 |
Map showing my known ancestor's birth
places in Europe |
What am I seeing the most? Probably West German. This is very accurate, I have a lot of West German ancestry on both sides of my tree, and I estimate it makes up about 25% of my tree. I also have a couple Swiss-German branches, which is still fairly consistent with West German. There's one ancestor who was from Bavaria, which is a region of Germany more to the east, but I have no idea what part of Bavaria - could have been the western most part for all I know. What I do know is that I rarely ever get admixture/ethnicity results in Eastern Europe and when I do, it's normally in such small portions, it's likely noise. So this is all very consistent with my tree.
I'm also seeing South Italian and some other Italian regions like East Sicilian and Abruzzo. This is incredibly accurate. I do indeed have Sicilian, Abruzzo, and other Southern Italian ancestry. My paternal grandmother was of entirely Italian descent so that makes up another 25% of my tree. My Sicilian branch is a bit more Northern Sicily than Eastern, but that's fairly negligible. There's one count of Tuscan and as far as I know I have no Tuscan ancestry, but that too is probably not very significant since it only shows up once.
There's a few West Norwegians thrown in there, which is also accurate, I have one great grandparent who was Norwegian, making up 12.5% of my tree. Several branches were indeed from Western Norway, although one branch did come from the more Eastern towns of Bamble and Skien.
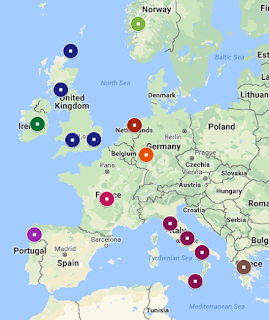 |
Map showing my population results for
Eurogenes K15 Oracle 4, compare with above map |
You may also notice a few Orcadian and West Scottish populations. This is somewhat accurate, I do have several Scottish or Scots-Irish branches dating back to colonial times, but where exactly in Scotland they were from isn't really known. Orcadian (people from the Orkney Islands) seems a little unlikely as my understanding is most Orcadian immigrants went to Canada through the Hudson Bay Company rather than the US. But if we consider Orcadian as a representation of my Scottish or even British heritage, it makes sense. The Orcadians were also influenced by the Vikings, so there's also a potential connection to my Norwegian side. My overall British branches make up about 34% of my tree, and in addition to Scottish, includes English, so it's not surprising to find a few instances of Southeast or Southwest English. As you can see from the map above, I do indeed have ancestry in Southwest and Southeast England, although I have more recent roots in Northern England, near Manchester so it's a shame it didn't pick this up. It's possible Oracle is underestimating my British ancestry, since there's only a few English populations included, but when you consider how genetically similar the British and Germans are, and knowing how many instances of West German are listed, it makes some sense.
I lastly have a smidgen of colonial Dutch and French Huguenot in my tree but I don't know how realistic it is to expect that to show up in admixture results, as it may have been from too long ago. They make up about 1-2% each of my tree. So when I see a few results for North Dutch and French, I'm taking it with a grain of salt. I'd like to think it could be from colonial ancestry but the way Oracle works by identifying the populations you match most closely, it doesn't seem likely I would closely match a population from so far back in my tree. It seems more likely that it's just being picked up from neighboring regions where I have ancestry.
Likewise, I wouldn't put much thought into the remaining few instances of Italian Jewish, Central Greek, Irish, and Spanish Galicia. Irish is probably just representing my British background, as those two groups are closely related, and likewise, Italian Jewish, Central Greek, and Spanish Galicia may be related to my Italian heritage since they're all from that Mediterranean area. In any case, since there's only one or two counts of them, it's easy to ignore them.
So overall, despite the fact that it doesn't always identify my British/English ancestry as much as it maybe should, it's actually remarkably accurate when you look at it on the whole. Compare the two maps above, one showing the origins of my ancestors and the other showing my Oracle results, and they really aren't far off each other (keeping mind some of the locations for the Oracle map cover a larger area than what the pinpoints represent). Mapping it out is another good, fun way to analyze your admixture or Oracle results, if you'd like to try it, just go to
My Google Maps.
I don't normally worry too much about the distance unless it starts getting really high. For example, K13's Oracle has closer distances than K15, but the populations in K15 are far more accurate for me than K13. I am NOT saying K15 is the best option for everyone. When I look at my dad's K15 Oracle results, they are mostly inaccurate, constantly insisting he is Lebanese Druze, which seems very off base. I can't even promise that there will be an Oracle calculator that is as accurate for you as Eurogenes K15 is for me, since I haven't really found one for my dad that is this accurate (he does get a lot of Abruzzo results in various calculators, which is accurate, but there's also a lot of populations that are kind of out there for him).
Also keep in mind some of the calculators contain a lot of ancient (prehistoric) populations. If you see some weird names like "Battle Axe" or "Bell Beaker", these are probably ancient populations (Battle Axe is Neolithic, Bell Beaker is western Europe in late Neolithic-early Bronze Age).
I hope this gives some more detailed insight in how you might interpret your own Oracle results. If you are adopted and don't know your ancestral background, it's difficult to know which calculators will be more accurate than others. You should definitely still take all this with a grain of salt, but it is fun to examine and compare with what we do know.