|
| My new results |
As discussed previously, there is an update in the works for AncestryDNA's Ethnicity Estimate, currently still in beta mode,
you may be able to manually access it as detailed here. Three out of my five kits were able to update - but are the new results actually better, or more accurate? In some ways, yes, and for certain people, yes. But in other ways, and for certain people, a definite no. It seems to work best for people who are less mixed. For example, if your ancestry is entirely English, versus someone who is English, German, Italian, etc then you very well might be finding that the new results are more consistent with your tree. It seems for those of us who come from various backgrounds, the ethnicity report can be a little bit all over the place, and not in a way that is consistent with our known ancestry.
 |
| My old results |
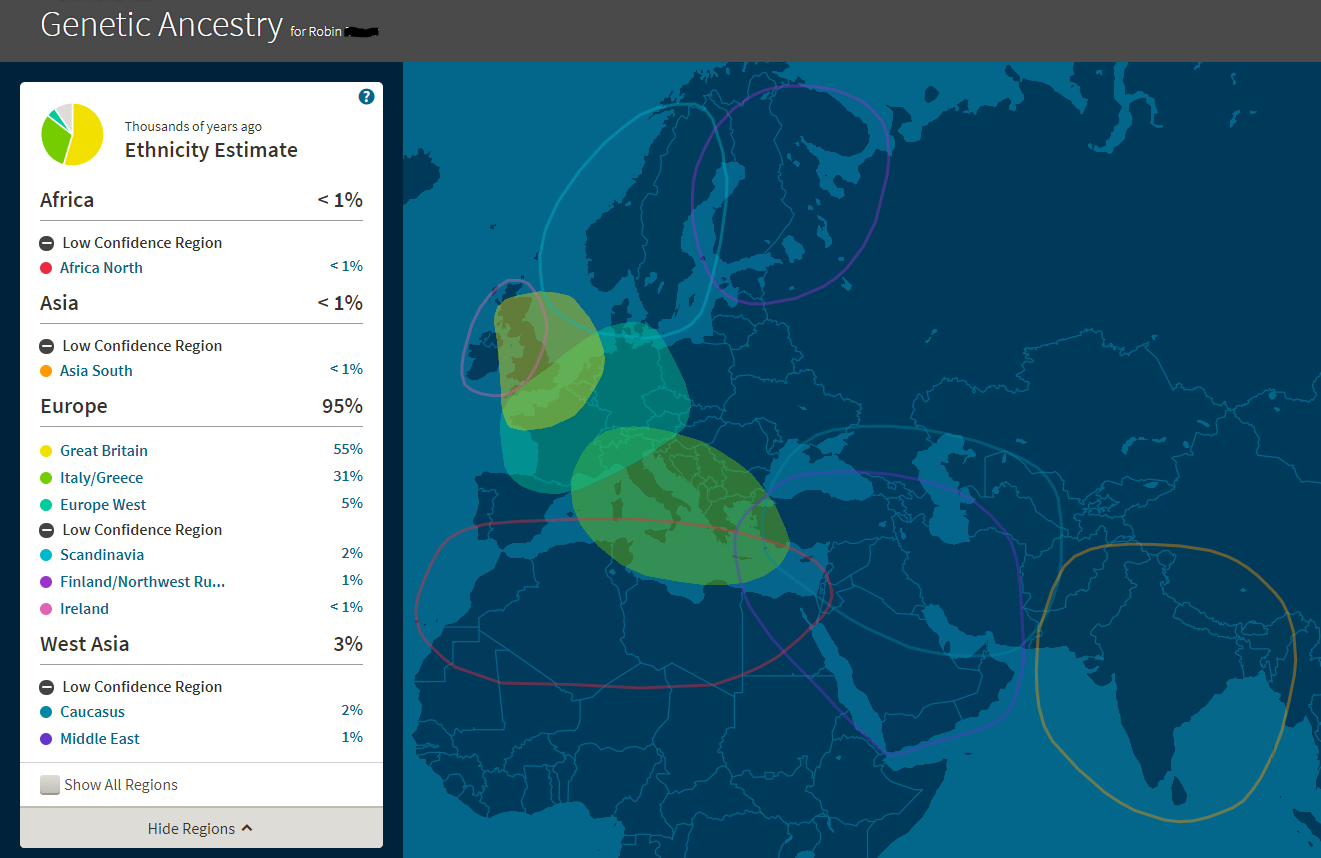
I'll start with myself. As I'm sure I've mentioned many times, I am a mix of British, German, Italian, and Norwegian (and a little bit of Dutch and French Huguenot, but that may be from too far back for the ethnicity report to be relevant). The new update (shown above) seem to be a bit thrown off from my variety of admixture.
Granted, they do seem to have dropped most of the results from outside Europe I had before (see right), which is more consistent with my tree. I am now 99% European and only 1% Turkey/Caucasus, whereas before I only had 95% in Europe.
However, I'm still getting a lot of low percentages in areas surrounding where my ancestry comes from (2% Spain, 2% Greece/Balkans, etc), they are just now mostly in Europe instead of outside it. I also notice that AncestryDNA have done away with labeling "low confidence regions", which were previously defined as "when an ethnicity has a range that includes zero (meaning that in at least one of the 40 tests, that ethnicity didn’t appear) and doesn’t exceed 15%, or when the predicted percentage is less than 4.5%". Now, results which fall into this are no lower identified as such, suggesting that AncestryDNA are much more confident about even low percentage results/ranges. Sadly, I'm not convinced they have earned that confidence.
Due to the fact that my paternal grandfather tested, I know I share 18% of my DNA with him, rather than the "expected" 25% (this is normal), which means I inherited 32% from my Italian paternal grandmother. Before the update, AncestryDNA estimated my Europe South component at almost exactly what it should be: 31%, so I should have known that any deviation from this was going to be a step in the wrong direction, but the mere 12% Italian was still somewhat of a shock. Even if I add up the small amounts in surrounding areas for a Southern European total, I'm still only up to 17%. Not only was AncestryDNA's original prediction consistent with my tree, it was also very consistent with most other companies. FTDNA gave me 33% in Southern Europe, 23andMe had me at 29.5% Southern Europe, and LivingDNA at 30.2%. The only outlier was MyHeritage at 41.6%, which is partly why I felt MyHeritage's reports were less reliable than everyone else. But now, AncestryDNA must join the ranks of MyHeritage. My Northern vs Southern European ancestry has always been easy for most companies to tell apart so this seems like a big step in the wrong direction for me.
There are, of course, other discrepancies between the new report and my tree, but they are less severe. Although AncestryDNA is attempting to narrow regions down to more specific areas, it's not always reliable. I do not have as much French ancestry as they are suggesting at 18%, but if you add it together with Germanic, another 18%, you get 36%, which isn't that far off what I estimate from my known ancestry (about 21% German/Swiss/Dutch). So in some cases, I think we still need to look at broader areas and combine neighboring regions despite AncestryDNA's attempt to break them down.
 |
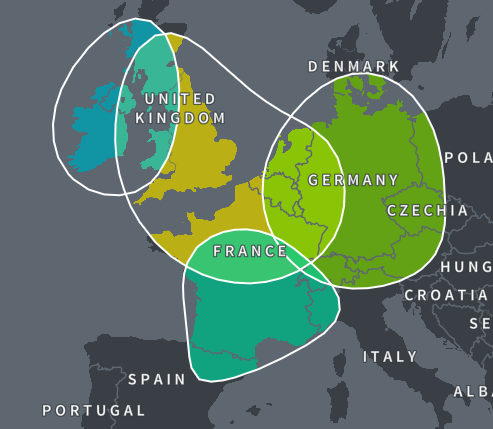
| Great Britain - old ethnicity map |
Of little consolation is the fact that my 7% in Norway is a little closer to what I might expect to have gotten from my one Norwegian great grandfather, and my England/Wales results are exactly what I estimated my tree to be, 32%, whereas before it was a bit overestimated at 55% Great Britain.
This brings me to the point I want to make about the new regional names of the British Isles. Despite the name change, we're not actually seeing any difference in the areas these groups primarily cover.
Previously, Great Britain (map shown above/right) was defined as:
Primarily located in: England, Scotland, Wales
Also found in: Ireland, France, Germany, Denmark, Belgium, Netherlands, Switzerland, Austria, Italy
 |
England, Wales, and NW Europe
new ethnicity map |
And now "England, Wales, and Northwestern Europe" (map shown right) is defined as:
Primarily located in: England, Scotland, Wales
Also found in: Ireland, France, Germany, Denmark, Belgium, Netherlands, Switzerland, Luxembourg
So despite the name change, they both primarily cover England, Scotland, and Wales - the only change was to a couple of the secondary regions it might cover (no more Italy and Austria, but Luxembourg was added).
The same is true for what was previously called "Ireland/Scotland/Wales" (map shown below):
Primarily located in: Ireland, Wales, Scotland
Also found in: France, England
 |
Ireland/Scotland/Wales - old
ethnicity map |
And now the new "Ireland and Scotland" (map shown below/left):
Primarily located in: Ireland, Wales, Scotland
Also found in: France, England
As you can see from the descriptions, it's exactly the same coverage.
So don't let the new names fool you, "England, Wales, and NW Europe" doesn't cover mainland Europe any more strongly than it did before, and it doesn't mean ancestry from Scotland (or even Ireland) can't still turn up under this category. I do not know why they are adding "Northwestern Europe" to the title of this group when it is not listed under the locations it's primarily found in. I expect this will undoubtedly be confusing to some people. Likewise, Wales may have been dropped from the now named "Ireland and Scotland" but you can see from the description and maps that it's still included in this group as a primary location.
This is why it's so important to look at the details and not just go off the category title.
As you can see from the coverage maps I've also included, those haven't changed much either. They appear to have only changed the maps to better reflect the descriptions, not because the descriptions have changed. For example, previously Great Britain didn't list Norway in it's description of "also found in", yet the map did cover the southern tip of it, whereas now it does not. Previously, the map for Ireland, Scotland and Wales did not cover France even though it was included in the description, but now it does. So although the maps have changed slightly, it's not because the category is primarily covering any different areas.
It should be noted that although the regions these groups cover haven't changed, that doesn't mean your results in those categories won't. AncestryDNA have significantly updated their reference panel from 3,000 to 16,000, so we are seeing changes to the genetic make up of these groups in the reference panel, which will very likely reflect changes to the percentage you get in those categories.
Obviously, mainland Europe is seeing significant changes to the breakdown and coverage of different regions. Europe West, previously "primarily located in": Belgium, France, Germany, Netherlands, Switzerland, Luxembourg, Liechtenstein and "also found in": England, Denmark, Italy, Slovenia, Czech Republic is now broken down into "France" and "Germanic Europe", which respectively cover:
Primarily located in: France
Also found in: Andorra, Belgium, Italy, Luxembourg, Monaco, Spain, Switzerland
Primarily located in: Germany
Also found in: Netherlands, Belgium, Switzerland, Austria, Czech Republic, Denmark
Unfortunately I don't have the room or time to detail every new region, especially with maps, but you can see from the completely list how different the breakdown for Europe is now:
Europe
- Baltic States
- Basque
- Eastern Europe and Russia
- England, Wales & Northwestern Europe
- European Jewish
- Finland
- France
- Germanic Europe
- Greece and the Balkans
- Ireland and Scotland
- Italy
- Norway
- Portugal
- Sardinia
- Spain
- Sweden
And for the rest of the world:
Africa
- Africa South-Central Hunter-Gatherers
- Benin/Togo
- Cameroon, Congo, and Southern Bantu Peoples
- Eastern Africa
- Ivory Coast/Ghana
- Mali
- Nigeria
- Northern Africa
- Senegal
America
- Native American—Andean
- Native American—North, Central, South
Asia
- Balochistan
- Burusho
- Central and Northern Asia
- China
- Japan
- Korea and Northern China
- Philippines
- Southeast Asia—Dai (Tai)
- Southeast Asia—Vietnam
- Southern Asia
- Western and Central India
West Asia
- Iran/Persia
- Middle East
- Turkey and the Caucasus
Unfortunately, Africa and Pacific Islander don't see any further breakdown but that doesn't mean you won't see changes to your percentages or regions. America only see the addition or distinction of Andean, and West Asia sees a two part area now split into three. The biggest changes aside from Europe have happened in Asia, and it's about time. Ancestry's previous Asian groups only covered three very large regions: Asia Central, Asia East, and Asia South. Now there's 11 regions! I frequently used to recommend East Asians wanting to take a DNA ethnicity test to go with 23andMe, not AncestryDNA, but now I don't have to.
It should be noted that the update does not influence your Genetic Communities or Migrations. You might find some of them are now organized under a new parent region due to the new breakdown of the regions, but that's the most of it. The Genetic Communities/Migrations are determined through different methods using a different reference dataset (which is precisely why I still believe they shouldn't have been merged as sub-regions as though they are the same) so they aren't going to change with this update.
I think that covers enough for now. I will detail the changes to my other kits in another article.