Recently AncestryDNA added yet another feature to their DNA tools, a Chromosome Painter. It shows us which portions of our chromosomes they have identified as coming from which regions. It's found under SideView because there's also a breakdown by Parent 1 and 2. AncestryDNA joins 23andMe and FamilyTreeDNA in offering this feature (leaving MyHeritage as the odd man out), so I decided it was time to compare them.
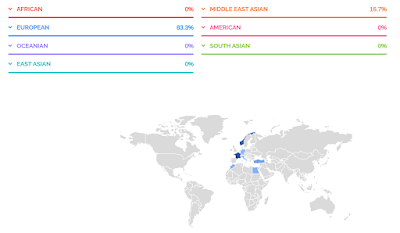
For me, it's easiest to analyze my Italian ancestry since it's genetically more distinct from the rest of my ancestry which is Northwest European. At Ancestry, it's mostly identified correctly as Southern Italy (22%), and some as Northern Italy (9%). At 23andMe, it's primarily put into Italy (23.6%), with a little bit in Greece/Balkans (1.6%), Cyprus (3.2%), and Anatolia (1.6%). A few other less than 1% results in various Southern Europe/West Asia areas add up to only 1.2%. FamilyTreeDNA isn't quite as accurate, but at least they get most of it in Southern Europe, with 28% in Greece/Balkans and only 8% in the Italian Peninsula. However, as you can see, the totals add up to approximately the same amounts at each company: 31% at AncestryDNA, 31.2% at 23andMe, and 36% at FTDNA. This is consistent with the fact that my paternal grandmother was Italian and since my paternal grandfather tested, I know I share 18-19% (depending on the company) with him, leaving 31-32% I obviously got from my Italian grandmother (totaling the 50% from my dad).
Knowing that the percentages are fairly consistent, I wanted to see if the individual segments identified in these regions would be consistent across all companies as well. Overall, there was reasonable consistency between 23andMe and AncestryDNA, but FTDNA was all over the place. Let's look at it chromosome by chromosome, at least on a few of them (I don't think I need to go over all 22 of them).
Chromosome 1
AncestryDNA shows almost the full length of one side of chromosome 1 is Southern Italian (above), apart from a small portion at the end. 23andMe shows the first and last portions of the chromosome as Italian (below, first), with the middle bit missing, but interestingly, it seems at least some of that middle bit is identified as Cypriot (below, second).
Obviously, there's some overlap there and it's saying they're on opposite sides, but there's no way either Italian or Cypriot is coming from my mom's side since she is 100% Northwest European - British, German, Norwegian. So although it may not align perfectly, it does seem to suggest nearly the full length is coming from Italy/Cyprus, which is mostly consistent with AncestryDNA.
Unfortunately, FTDNA isn't as consistent with the other two companies. As you can see (above), the Southern European (light blue) portions are much more broken up, although I suppose one side does seem to be be mostly Southern European. The dark blue portions are Western European, FTDNA's chromosome painting doesn't offer any more breakdown than that and doesn't allow me to isolate the different regions in the visual.
Chromosome 2
On chromosome 2, AncestryDNA (below, first) and 23andMe (below, second) are almost exactly the same. They both put essentially the entire length of one side of the chromosome in Italy (Northern Italy at AncestryDNA), though there's a tiny sliver at the end at 23andMe which they deemed Broadly NW European, that's probably not a significant amount.
But here again, at FTDNA, the results are so inconsistent that it almost seems random (below).
Although one side has more Southern European (light blue) than the other, it's so broken up and looks so similar to chromosome 1, it just doesn't seem very reliable.
Chromosome 3
The results on chromosome 3 are exactly the same at AncestryDNA (below, first) and 23andMe (below, second), while FTDNA (below, third) is once again not as consistent.
I suppose FTDNA has a little more solid light blue than previous chromosomes, but it's not the full, unbroken length we see at AncestryDNA and 23andMe. That little sliver of green is Middle East.
Chromosome 4
This one is also very consistent between AncestryDNA and 23andMe, but for the opposite reason - both companies say no portion of either side of chromosome 4 comes from anywhere in Southern Europe or West Asia. Here we can analyze some of my Northwest European ancestry a little bit. 23andMe (below, second) says both sides of the chromosome are NW European, primarily from France/Germany (light blue), with smaller portions unable to narrow down and identified as Broadly NW European (grey/missing portions). At AncestryDNA (below, first), the entire length of one side is identified as Scottish (lime green), and the full length of the other side is categorized as Norwegian (light blue). This is extremely consistent with my known ancestry - my paternal grandfather was mostly German and Scottish, while my mom is part Norwegian. 23andMe only gives me a small percentage of Scandinavia though, with none of it on chromosome 4. None of this surprises me, since British, Germanic, and Scandinavian have a lot of genetic overlap and are difficult to tell apart, so who knows which company is right, but at least they both agree that both sides of chromosome 4 are NW European.


Not so much with FTDNA (below). Although they do identify most of both sides as Western Europe (dark blue), there are still portions of Southern Europe (light blue) seemingly randomly thrown in there.
At this point, it doesn't even seem worth carrying on comparing FTDNA. The rest of every chromosome is pretty much the same as what I've already shown here. Although the amounts of Western vs Southern Europe vary somewhat in vague keeping with the other two companies, the minimal variation is not worth going into a detailed comparison.
Chromosome 8
I want to skip ahead now to chromosome 8. Chromosomes 5, 6, and 7 are exactly the same at both AncestryDNA and 23andMe - both companies identified the exact same portions as either Italian or Southern European. Chromosome 8 is the first time we really see a significant difference in what the two companies report.
AncestryDNA (above, first) estimates that roughly the second half of one side of chromosome 8 is from Southern Italy (teal), while the first half is Scottish (lime green), and the other side is supposedly from Sweden/Denmark (pink). I don't have any ancestry from Sweden or Denmark, and AncestryDNA puts my combined Scandinavian percentage a little high, and my Germanic a little low, so I'm assuming it's probably coming from my German ancestry.
However, 23andMe (above, second) doesn't identify any Italian or Southern European (or West Asian, for that matter) on chromosome 8 at all. It estimates one side is entirely French/German (light blue), and the rest (grey) is mostly Broadly NW European with a small portion in Scandinavia.
So the portion AncestryDNA deems Italian, 23andMe says is Germanic.
Chromosomes 9-22
The rest of my chromosomes probably aren't worth going into visual detail, but here's a quick summary:
Chromosome 9 - AncestryDNA estimates the full length of one side is Northern Italian while 23andMe says only half of that side is Italian/Southern European.
Chromosome 10 - AncestryDNA claims about the first third of one side is Southern Italian, but 23andMe puts that portion (which is more like the first half of the chromosome) in Cyprus.
Chromosome 11 - AncestryDNA puts the full length of one side in Northern Italy, and 23andMe says most of that is Anatolian.
Chromosome 12 - AncestryDNA reports no Italian ancestry at all, but 23andMe says about half of one side is Italian.
Chromosome 13 - Again, nothing Italian from AncestryDNA and this time, 23andMe agrees (nothing from Southern Europe of West Asia).
Chromosome 14 - Ancestry estimates the full (tested) length of one side is Southern Italian. 23andMe says most of one side is either Italian or Arab/Egyptian/Levantine.
Chromosome 15 and 16 - Both companies agree the full (tested) length of one side is from Italy (specifically Southern Italy at AncestryDNA).
Chromosome 17 and 18 - Both companies agree there's no sign of Southern European or West Asian ancestry at all.
Chromosomes 19, 20, 21 - Both companies agree the full (tested) length of one side is from Italy (specifically Southern Italy at AncestryDNA).
Chromosome 22 - Both companies agree the full (tested) length of one side is from Italy (specifically Northern Italy at AncestryDNA).
Although there's some variations on a few chromosomes, overall I'd say the AncestryDNA and 23andMe are very consistent with each other. FTDNA was so inconsistent I literally gave up comparing it.
Here it's worth noting that 23andMe include ethnicity on the X chromosome where neither AncestryDNA or FTDNA do. To my knowledge, 23andMe are the only ones to use the X chromosome for ethnicity, though admittedly I don't know about MyHeritage since they neither offer a white paper or a chromosome painter. At 23andMe, it identifies one side of my X chromosome as French/German (my mom's side) and the other side as mostly Italian (dark blue) from my dad's Italian mother. The small portion at the end of that side is classed as Broadly Northwest European (lightest blue).

For the record, X-DNA makes up only about 5% of all your chromosomes. Some people point out that at 23andMe, a man's ethnicity report will include more DNA from his mother than his father because men only get X-DNA from their mother, not their father. Women get one X chromosome from their mother, one from their father, meaning it's still 50/50 just like with the autosomal chromosomes. Instead, men get one X chromosome from their mother and one Y chromosome from their father, but Y chromosomes aren't used for ethnicity (ever), so they will have slightly more DNA from their mother than their father on the ethnicity report. This is true, but it's worth noting that one X chromosome only amounts to about 2.5%, which is also within "noise" level amounts. So we're not talking about a significant or noteworthy difference.